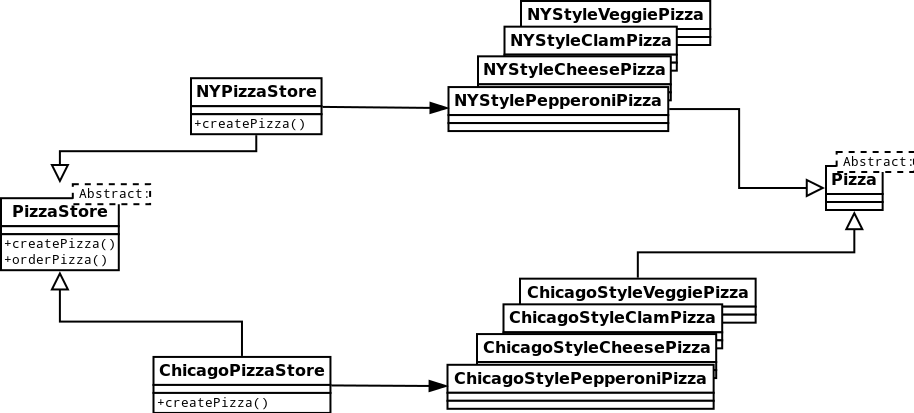
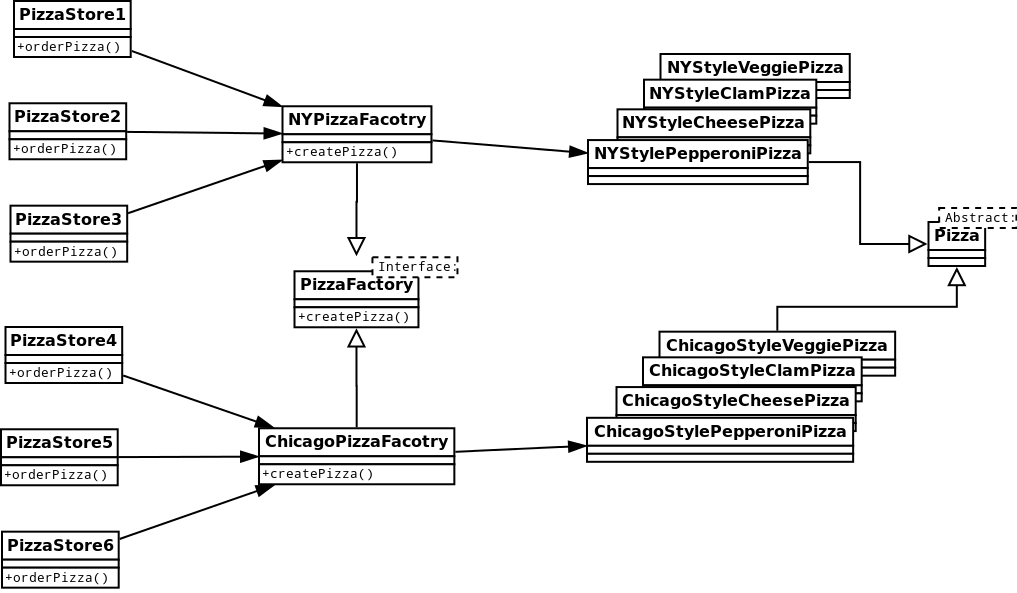
JUnit是由Erich Gamma和Kent Beck编写的一个开源的单元测试框架。它属于白盒测试,只要将待测类继承TestCase类,就可以利用JUnit的一系列机制进行便捷的自动测试了。
JUnit的设计精简,易学易用,但是功能却非常强大,这归因于它内部完善的代码结构。JUnit中深深渗透了扩展性优良的设计模式思想。JUnit提供的API既可以让您写出测试结果明确的可重用单元测试用例,也提供了单元测试用例成批运行的功能。在已经实现的框架中,用户可以选择三种方式来显示测试结果,并且 显示的方式本身也是可扩展的。
###JUnit系统架构
通过分析JUnit-3.8.1的源代码文件可以看到,JUnit的源码被分散在6个package中,这个6个package分别为:junit.awtui、junit.swingui、junit.textui、junit.extensions、junit.framework、junit.runner。具体的文件分布图如下:

通过对源码的分析,我们可以知道,其中junit.awtui、junit.swingui、junit.textui这三个package是有关JUnit运行时的入口程序以及运行结果显示界面的,junit.runner中则包含了支持单元测试运行的一些基础类以及自己的类加载器,这四个package的运行逻辑对于JUnit的用户来说,都是透明无法感知的,用户只能感知到JUnit测试时的运行界面以及相关的运行结果的展示。junit.extensions、junit.framework这两个package则是JUnit中的核心部分了,其中junit.framework 包含有编写一般JUnit单元测试类必须是用到的JUnit类;而junit.extensions则是对framework包在功能上的一些必要扩展以及为更多的功能扩展留下的接口。
通过对JUnit源码的package分析,可以得到以下三个package的类图:
1.junit.framework的类图

2.junit.extensions的类图

3.junit.runner的类图

###JUnit工作流程解析
Junit的主要功能就是简化单元测试,由于其代码中使用了很多的设计模式,因此纯粹从源码的角度分析其工作流程相对比较复杂,因此此处使用一个简单的测试用例来描述Junit的工作流程,这样会更容易理解其流程时序。

这段代码为一个我们将要测试的类,其中只有一个简单的add()方法,其功能是实现两个double类型的数值相加。
接下来我们将会对其编写对应的JUnit测试代码。

在上述测试代码中,我们的测试类TestCalculator继承了TestCase类(当然,我们还有一种编写方式不用继承TestCase类,但是我们需要在每个测试方法上添加@Test的注解),在测试类中,我们编写了testAdd()测试方法,同时一个必然失败的测试方法testFail(),这样可以便于我们更全面的了解JUnit运行机制。
通过对上述测试代码的分析以及JUnit源码的分析,我们可以为此次的用例总结出以下的时序图,这张图为我们清楚的展示了JUnit实现单元测试的内部机制。

JUnit的完整生命周期分为3个阶段:初始化阶段、运行阶段和结果捕捉阶段。
1.初始化阶段:

通过分析源码,可以看到JUnit的入口点在junit.textui.TestRunner的main方法,在这个方法中,首先创建一个TestRunner实例aTestRunner,然后main函数中主体工作函数为TestResult r = aTestRunner.start(args)。此时TestRunner实例存在并开始工作。接下来进入start()方法中:

首先,对于参数的检查和解析。接下来通过Test suite= getTest(testCase)将对testCase持有的全限定名进行解析,并构造TestSuite。进入getTest方法中:

在这段代码中,TestSuite实例开始被构造,而通过代码可以知道,构造方式分为:用户在测试类中通过声明Suite()方法自定义TestSuite和JUnit自动判断并提取测试方法两种方式。接下来就进入TestSuite类中构造方法public TestSuite(final Class theClass)。

在这中间,可以可以看到测试用例由addTestMethod方法全部添加到TestSuite中,继续跟进addTestMethod方法:

在这中间可以看到addTestMethod的具体实现,主要的就是addTest,其实这个方法只是简单封装了一个对全局的容器变量fTests的添加值操作。最重要的还是那个createTest方法,进入看看细节:

在这中间就可以看到各个测试用例方法通过反射机制:test= constructor.newInstance(new Object[]{name})转化成一个个TestCase实例。
至此,JUnit的初始化过程就结束了。
2.测试运行阶段:
在TestRunner中的start()方法中可以看到开始调用doRun()方法开始执行测试了。

进入doRun()方法中可以看到:

首先是利用createTestResult()方法生成一个TestResult实例,而createTestResult()方法其实也就是new一个TestResult实例,然后将junit.textui.TestRunner的监听器fPrinter加入到result 的监听器列表中。其中,fPrinter是junit.textui.ResultPrinter类的实例,该类提供了向控制台输出测试结果的一系列功能接口,输出的格式在类中定义。ResultPrinter类实现了TestListener接口,具体实现了addError、addFailure、endTest和startTest四个重要的方法,这种设计体现了Observer设计模式。而将ResultPrinter对象加入到TestResult对象的监听器列表中,因此实质上TestResult对象可以有多个监听器显示测试结果。
接下来我们查看run方法,可以看到:

此处JUnit代码颇具说服力地说明了Composite模式的效力,run接口方法的抽象具有重大意义,它实现了客户代码与复杂对象容器结构的解耦,让对象容器自己来实现自身的复杂结构,从而使得客户代码就像处理简单对象一样来处理复杂的对象容器。每次循环得到的节点test,都同result一起传递给runTest方法,进行下一步更深入的运行。
在这样递归的运行之后, junit.framework.TestResult.run相应的结果TestResult实例中:


这中间实现了Protectable接口的匿名类的实例,runProtected则是实际把那个刚刚实现的匿名类实例中的runBare()方法执行了。

在该方法中,最终的测试会传递给一个runTest方法执行,注意此处的unTest方法是无参的,注意与之前形似的方法区别。该方法中也出现了经典的setUp方法和tearDown方法,追溯代码可知它们的定义为空。用户可以覆盖两者,进行一些fixture的自定义和搭建。这中间其实就蕴含了模板模式的思想了。
其中,最为主要的还是runTest()方法:

在这里,通过反射机制runMethod= getClass().getMethod(fName, null);提取TestCase中的方法,然后为每一个测试方法,创建一个方法对象unMethod并调用runMethod.invoke(this, new Class[0]);,至此,用户测试方法的代码才开始真正被运行起来。当然剩下就是些异常捕获和处理。
3.测试结果捕捉阶段:
运行已经完成了,现在就是看结果了,当一切都是OK,当然是没问题啦。

当出现错误了或者失败,我们就catch到相应的Error或者Fail,然后用addFailure加入到监听器TestListener中,当然为了区分不同,还可以用addError添加。然后就可以由ResultPrinter将结果输出了:

###主要设计模式
JUnit中间,使用的设计模式是比较多的,JUnit应该来说是一个学习设计模式的很好的范例。
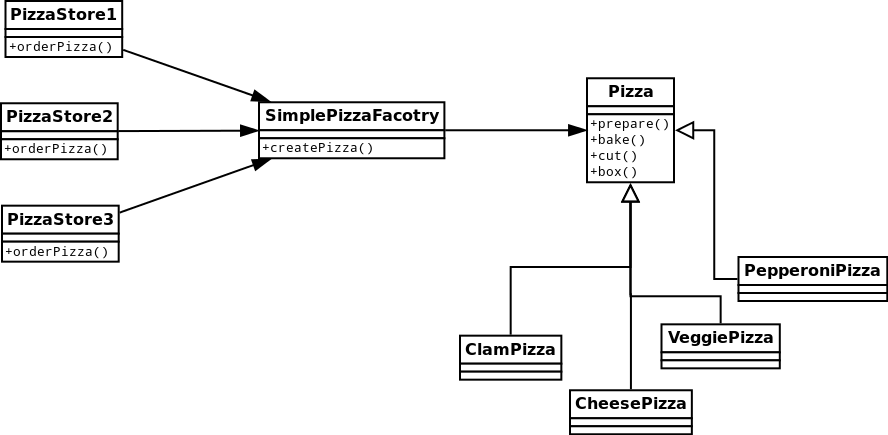
在前面的JUnit工作流程分析的单元中,分析过程中,我们已经看到了组合模式(Composite Pattern):
其中的run接口方法的抽象实现了客户代码与复杂对象容器结构的解耦,让对象容器自己来实现自身的复杂结构,从而使得客户代码就像处理简单对象一样来处理复杂的对象容器。
另外,TestCase中runBare()方法则是模板模式的典型范例:

这处则是充分体现了模板模式中将一些步骤延迟到子类中的思想。
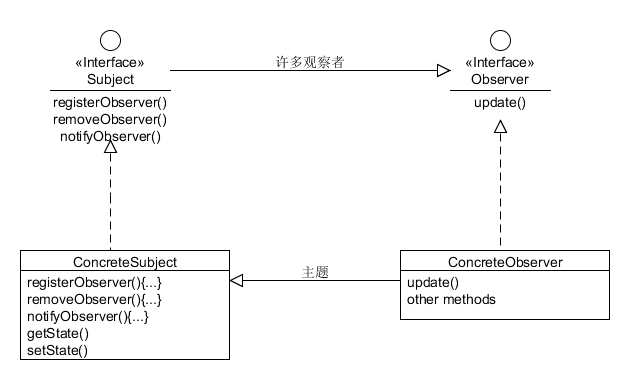
而观察者模式则是体现在下方:
TestResult并不是一个记录测试结果的类,而是观察者模式中的主题角色。每个TestCase运行的时候都是用TestResult来运行的,这样才能通知每个观察者方法要开始运行了。在这里,观察者就是那些显示方式,比如Text,Swing,Awt那几种UI的显示类。
命令模式则是表现在编写测试用例时,JUnit只是一个测试用例的执行器和结果查看器,而与实际用例的编写没有关联,处于完全解耦的状态。
###参考资料
[1]《分析JUnit框架源代码》,何正华、徐晔,http://www.ibm.com/developerworks/cn/java/j-lo-junit-src/
[2]《JUnit源码分析》,匿名,http://blog.csdn.net/ai92/article/details/318318
[3]《HeadFirst设计模式》,Freeman,E.,O’Reilly Taiwan公司译,中国电力出版社
[4] JUnit-3.8.1源码
]]>